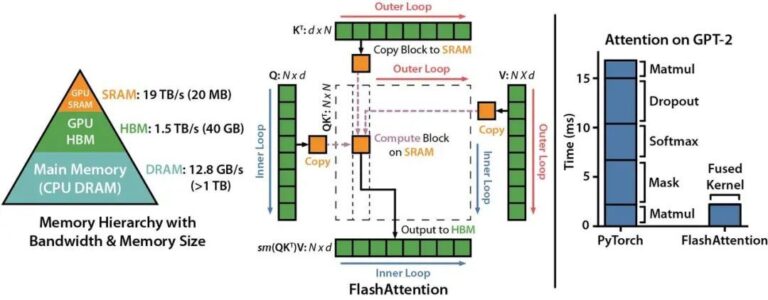
FlashAttention: A Novel Attention Algorithm with IO Awareness, Fast and Memory-Efficient
At the heart of the Transformer model is the self-attention mechanism, which has both time and storage complexity at the O(N2)O(N2) level in terms of sequence length. As the scale of large language models (LLMs) continues to grow, equipping LLMs with longer contextual backgrounds poses a significant engineering implementation challenge. A team of researchers from the Department of Computer Science at Stanford University and the State University of New York at Buffalo has published a novel attention algorithm called FlashAttention, which not only has a longer context than PyT