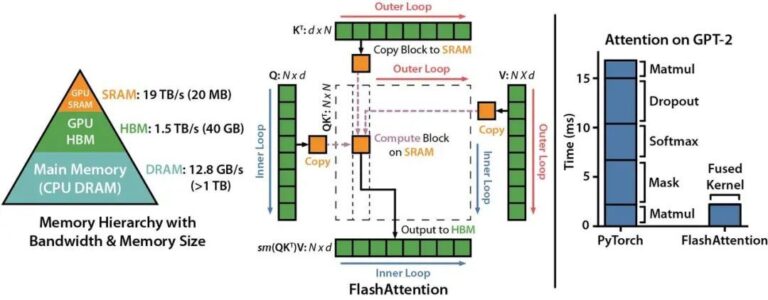
FlashAttention:具有 IO 感知,快速且内存高效的新型注意力算法
Transformer 模型的核心是自注意力机制(self attention),其在序列长度上时间和存储的复杂度都在 O(N2)O(N2) 级别。随着大语言模型(LLMs)规模的不断扩大,为 LLM 配备更长的上下文背景,在工程实现上面临着非常大的挑战。 来自斯坦福大学计算机系与纽约州立大学布法罗分校的科研团队发表了一种新型的注意力算法,名叫 FlashAttention ,其不仅拥有比 PyT
Transformer 模型的核心是自注意力机制(self attention),其在序列长度上时间和存储的复杂度都在 O(N2)O(N2) 级别。随着大语言模型(LLMs)规模的不断扩大,为 LLM 配备更长的上下文背景,在工程实现上面临着非常大的挑战。 来自斯坦福大学计算机系与纽约州立大学布法罗分校的科研团队发表了一种新型的注意力算法,名叫 FlashAttention ,其不仅拥有比 PyT
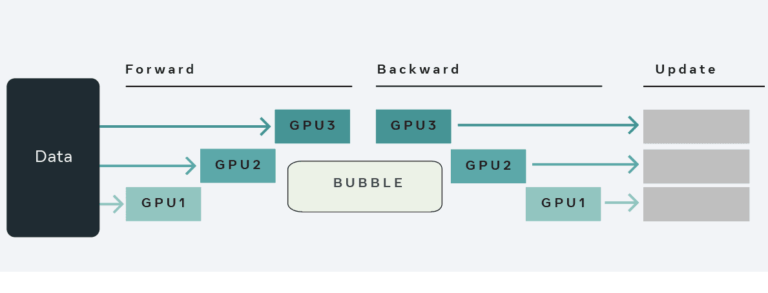
haiscale (Highflyer AI Scale) 是一个轻量级的高性能并行训练工具库,其整合了幻方 AI 多年的并行训练研发优化经验,能够帮助 PyTorch 用户更加高效、便捷地在大规模集群上训练模型。 haiscale 中包含了以下几种工具: haiscale.ddp: 分布式数据并行工具,以幻方 AI 自研的 hfreduce 通信为后端,相比于 NCCL 能够获得更好的多卡拓展性
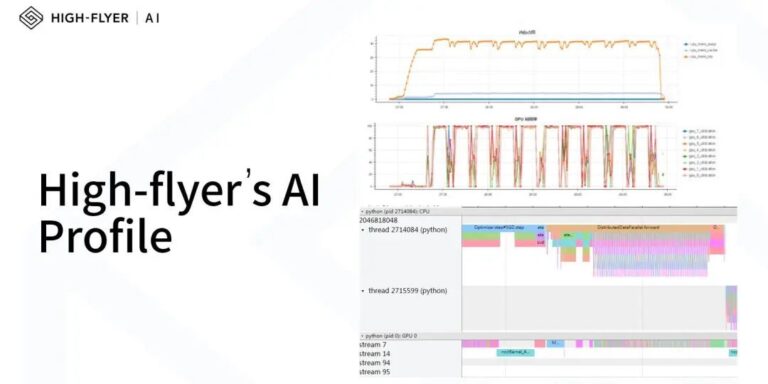
全世界都在给 GPT 的训练和推理算账,以至于微软会迫不及待地分享“每美元的推理能获得 2 倍的性能”的喜讯,其传递的信号或许是:一丁点的算力浪费,都在这场 AI 竞争里是致命的。 而越往后发展,模型训练效率的高低,越发成为科研人员不容忽视的难点。无论从加快训练测试更多参数,还是从节省研发成本的角度来说,低效的任务训练已经变得不可容忍。摆在眼前的,对于科研用户来说,一套趁手易用的模型性能分析工具,

“切勿错过AI的决定性时刻”这句 NVIDIA GTC 的广告语自周三起,一时间传遍全网。依照惯例,大会由熟悉的面孔黄仁勋围绕AI、芯片等科技,发布了一系列前沿技术产品。 今年幻方 AI 再度受邀,在 NVIDIA GTC 2023 大会中进行了一次技术主题分享。 自 2019 年起,我们为了满足自己科研作业的大规模算力需求,逐步构建了幻方萤火深度学习智算平台,其包括存储网络相关基础设施、分时调度

当下 AI 大模型如火如荼的发展,许多厂商开始构建起基于 GPU 的大规模深度学习训练集群。随着算力需求的扩大,一个能对 GPU 资源进行统一高效利用的 AI 平台,越来越成为各 AI 团队降本提效的重要武器。 构建一个能管理大规模 GPU 集群资源的 AI 平台,主要会遇到如下几个痛点问题: 资源调度:算力规模不断扩大,而训练任务的计算需求又多种多样,如何处理任务和算力的关系以最大化集群资源使用

AGI 是数据 x 算法 x 算力的完美实践,是科研 + 工程 + 组织的优雅艺术。而在大模型训练的前置阶段,大数据的清洗是数据处理的基础。 以 Common Crawl 数据集为例,它可以轻松地在 Amazon 上获取到,是一个免费的、规模达到 PB 级别的网络爬虫数据集,其包括了超过 12 年间收集到的数据:原始网页数据(WARC)、元数据提取(WAT)和文本提取(WET)。如何对庞杂的原始数

为了更好地发挥 GPU 集群的计算能力,训练具有惊人功能的、强大的万亿参数模型,一个高效简洁的大模型训练工具十分必要。幻方-基础研究最近研发了一款深度学习训练工具,名为 HAI-LLM,其实现了四种并行训练方式:ZeRO 支持的数据并行、流水线并行、张量切片模型并行和序列并行。这种并行能力适应了不同工作负载的需求,可以支持数万亿规模的超大模型并扩展到数千个 GPU。基于萤火集群的特性而自研的 ha