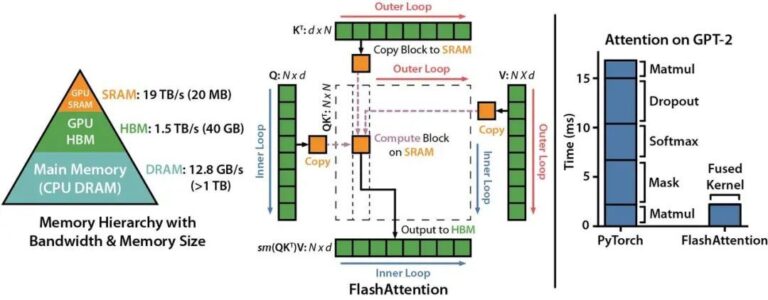
FlashAttention:具有 IO 感知,快速且内存高效的新型注意力算法
Transformer 模型的核心是自注意力机制(self attention),其在序列长度上时间和存储的复杂度都在 O(N2)O(N2) 级别。随着大语言模型(LLMs)规模的不断扩大,为 LLM 配备更长的上下文背景,在工程实现上面临着非常大的挑战。 来自斯坦福大学计算机系与纽约州立大学布法罗分校的科研团队发表了一种新型的注意力算法,名叫 FlashAttention ,其不仅拥有比 PyT
Transformer 模型的核心是自注意力机制(self attention),其在序列长度上时间和存储的复杂度都在 O(N2)O(N2) 级别。随着大语言模型(LLMs)规模的不断扩大,为 LLM 配备更长的上下文背景,在工程实现上面临着非常大的挑战。 来自斯坦福大学计算机系与纽约州立大学布法罗分校的科研团队发表了一种新型的注意力算法,名叫 FlashAttention ,其不仅拥有比 PyT

如文章《幻方力量 | 高速文件系列 3FS》中所介绍的,幻方AI设计了一套非常适合深度学习训练的样本读取文件系统,3FS,其采用 Direct IO 和 RDMA Read 的读取方式,让模型训练在样本读取部分只用极小的 CPU 和内存开销,就可以获得超高的读取带宽,从而无需再训练过程中等待加载数据,更充分地利用起 GPU 的计算性能。 我们知道,文件系统一般分为客户端与服务端。在 3FS 文件系
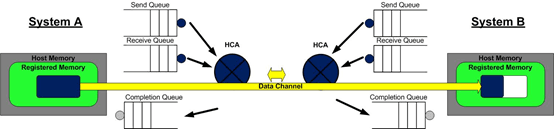
如文章《幻方力量 | 高速文件系列 3FS》中所介绍的,幻方AI设计了一套非常适合深度学习训练的样本读取文件系统,3FS,其采用 Direct IO 和 RDMA Read 的读取方式,让模型训练在样本读取部分只用极小的CPU和内存开销,就可以获得超高的读取带宽,从而无需再训练过程中等待加载数据,更充分地利用GPU的计算性能。 我们知道,文件系统一般分为客户端与服务端。在3FS文件系统中,客户端部
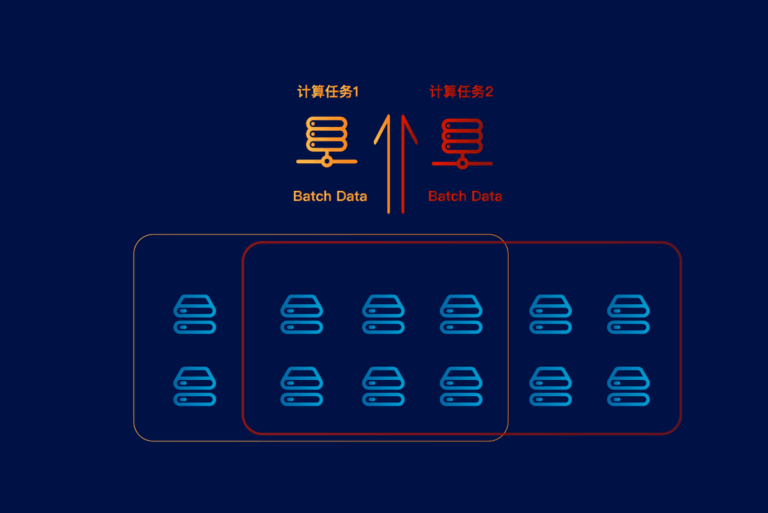
如文章《幻方力量 | 高速文件系列 3FS》中所介绍的,幻方AI设计了一套非常适合深度学习训练的样本读取文件系统,3FS,其采用Direct IO和RDMA Read的读取方式,让模型训练在样本读取部分只用极小的CPU和内存开销,就可以获得超高的读取带宽,从而无需再训练过程中等待加载数据,更充分地利用起GPU的计算性能。 然而,实际应用中会有很多我们之前没有预料到的问题,比如任务间互相影响的问题,