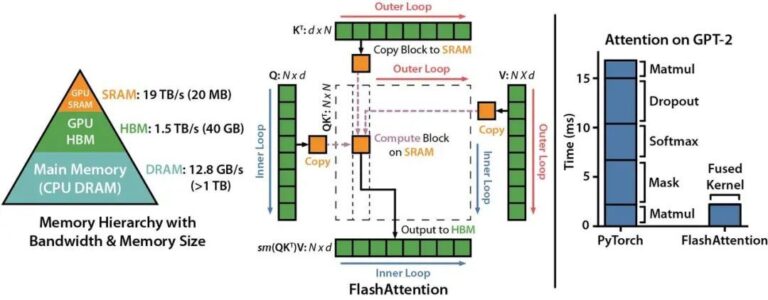
FlashAttention:具有 IO 感知,快速且内存高效的新型注意力算法
Transformer 模型的核心是自注意力机制(self attention),其在序列长度上时间和存储的复杂度都在 O(N2)O(N2) 级别。随着大语言模型(LLMs)规模的不断扩大,为 LLM 配备更长的上下文背景,在工程实现上面临着非常大的挑战。 来自斯坦福大学计算机系与纽约州立大学布法罗分校的科研团队发表了一种新型的注意力算法,名叫 FlashAttention ,其不仅拥有比 PyT
Transformer 模型的核心是自注意力机制(self attention),其在序列长度上时间和存储的复杂度都在 O(N2)O(N2) 级别。随着大语言模型(LLMs)规模的不断扩大,为 LLM 配备更长的上下文背景,在工程实现上面临着非常大的挑战。 来自斯坦福大学计算机系与纽约州立大学布法罗分校的科研团队发表了一种新型的注意力算法,名叫 FlashAttention ,其不仅拥有比 PyT

幻方 AI 发布了其沉淀多年的深度学习套件 hfai ,吸引了众多同行研究员和开发者们咨询试用。整个套件的功能较多,而熟悉掌握了这套规则,是能够轻松地调用起平台的算力资源,从而高效完成训练任务的。 为此,我们专门创建了 “hfai 使用心法” 系列专辑,分集陆续为大家介绍 hfai 一些功能的设计思路和原理,帮助大家更好更快地习得心法,带着 hfai 这套“神功”游刃有余的应对深度学习作业的各项挑

幻方 AI 发布了其沉淀多年的深度学习套件 hfai ,吸引了众多同行研究员和开发者们咨询试用。整个套件的功能较多,而熟悉掌握了这套规则,是能够轻松地调用起平台的算力资源,从而高效完成训练任务的。 为此,我们专门创建了 “hfai 使用心法” 系列专辑,陆续为大家介绍 hfai 一些功能的设计思路和原理,帮助大家更好更快地习得心法,带着 hfai 这套“神功”游刃有余的应对深度学习作业的各项挑战,

幻方 AI 发布了其沉淀多年的深度学习套件 hfai ,吸引了众多同行研究员和开发者们咨询试用。整个套件的功能较多,而熟悉掌握了这套规则,是能够轻松地调用起平台的算力资源,从而高效完成训练任务的。为此,我们专门创建了 “hfai 使用心法” 系列专辑,陆续为大家介绍 hfai 一些功能的设计思路和原理,帮助大家更快上手 hfai,游刃有余的应对深度学习作业的各项挑战。 之前的文章为大家介绍了使用
幻方 AI 发布了其沉淀多年的深度学习套件 hfai,吸引了众多同行研究员和开发者们咨询试用。整个套件的功能较多,而熟悉掌握了这套规则,是能够轻松地调用起平台的算力资源,从而高效完成训练任务的。为此,我们专门创建了“hfai 使用心法”系列专辑,陆续为大家介绍 hfai 一些功能的设计思路和原理,帮助大家更快上手 hfai,游刃有余得应对深度学习作业的各项挑战。 本终章为大家连贯的演示 hfai