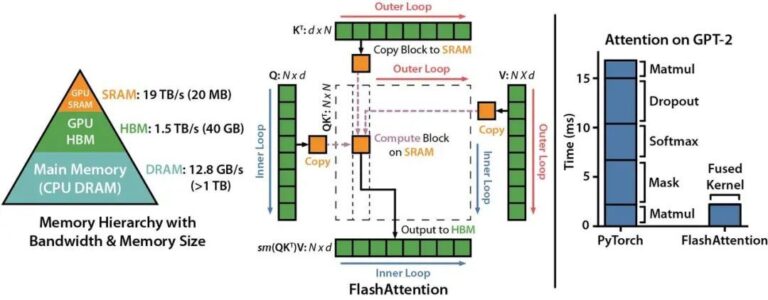
FlashAttention:具有 IO 感知,快速且内存高效的新型注意力算法
Transformer 模型的核心是自注意力机制(self attention),其在序列长度上时间和存储的复杂度都在 O(N2)O(N2) 级别。随着大语言模型(LLMs)规模的不断扩大,为 LLM 配备更长的上下文背景,在工程实现上面临着非常大的挑战。 来自斯坦福大学计算机系与纽约州立大学布法罗分校的科研团队发表了一种新型的注意力算法,名叫 FlashAttention ,其不仅拥有比 PyT
Transformer 模型的核心是自注意力机制(self attention),其在序列长度上时间和存储的复杂度都在 O(N2)O(N2) 级别。随着大语言模型(LLMs)规模的不断扩大,为 LLM 配备更长的上下文背景,在工程实现上面临着非常大的挑战。 来自斯坦福大学计算机系与纽约州立大学布法罗分校的科研团队发表了一种新型的注意力算法,名叫 FlashAttention ,其不仅拥有比 PyT

YOLO 系列模型在整个深度学习目标检测领域有举足轻重的地位,近些年模型性不断发展,工程落地中的应用也十分广泛。 最近来自美国的 Ultralytics 公司发布了第五代 YOLO 模型: YOLOv5。相比上代模型,YOLOv5 以更轻量的参数,更极致的推理速度,一经发布受到了学术界和工业界相关人士的广泛关注。 幻方 AI 最近在萤火集群上对该项工作进行了体验和优化。YOLOv5 没有相应的论文
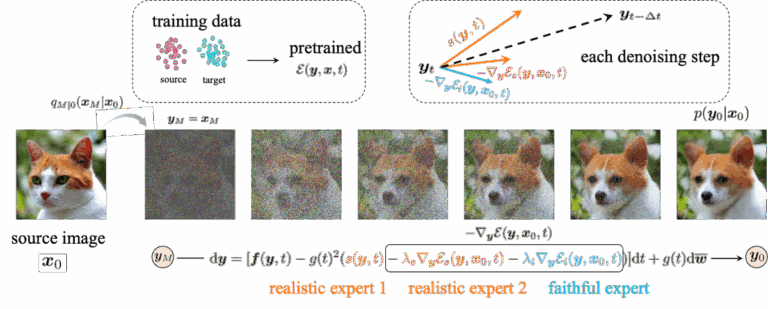
扩散模型作为一种新的深度生成模型,在图像生成领域取得了 SOTA 的效果,并且逐渐在诸多应用领域展现出强大的性能,如视频生成、分子图建模等。 最近来自人民大学李崇轩课题组的研究者们提出了一种基于能量函数的扩散模型生成指导方法 EGSDE。该方法旨在通过预定义的能量函数对预训练好的扩散模型进行指导,从而实现可控生成。现有指导生成方法如 classifier-guidance 等可以理解为 EGSDE
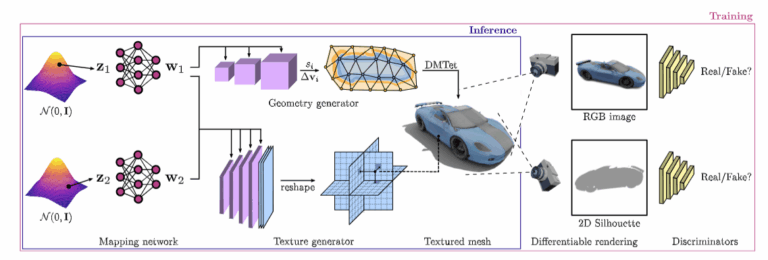
随着多个行业朝着大规模的 3D 虚拟世界发展,能够生成大量的、高质量的、多样的 3D 内容的工具是非常被需要的。英伟达的最新工作 GET3D 希望训练更好的 3D 生成模型,来生成下游任务可以直接使用的、保真纹理和复杂几何细节的 3D 模型。 幻方 AI 最近对这项工作进行了整理和优化,在幻方萤火二号上复现了实验。通过幻方自研的 3FS、hfreduce、算子,对模型训练进行提速,从单机多卡的训练
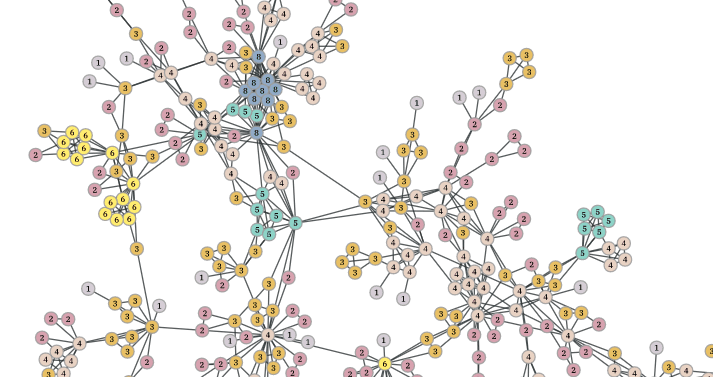
图(Graph)数据在现实世界中非常常见,例如社交网络、交通网络、物理系统等等,近几年图神经网络的发展将图数据的分析与深度神经网络结合,在越来越多的领域发挥出重要的作用,例如电商推荐、生物化学结构分析、反恐反诈风险控制等等。数据规模也呈现越来越大之势,动辄上千万节点规模的图,让很多图神经网络的训练需要探寻并行计算的方式以加速。 然而,图数据与视觉、自然语言等领域的数据不同,没有划分好的训练样本,很