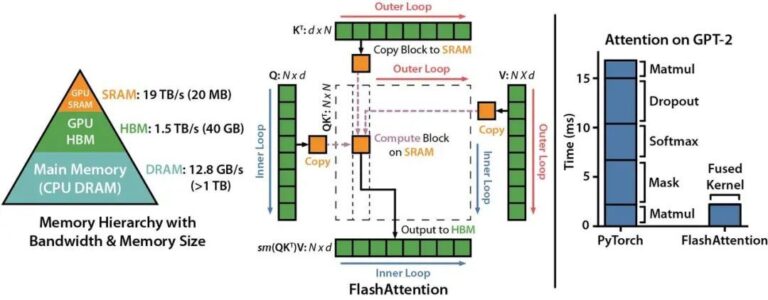
FlashAttention:具有 IO 感知,快速且内存高效的新型注意力算法
Transformer 模型的核心是自注意力机制(self attention),其在序列长度上时间和存储的复杂度都在 O(N2)O(N2) 级别。随着大语言模型(LLMs)规模的不断扩大,为 LLM 配备更长的上下文背景,在工程实现上面临着非常大的挑战。 来自斯坦福大学计算机系与纽约州立大学布法罗分校的科研团队发表了一种新型的注意力算法,名叫 FlashAttention ,其不仅拥有比 PyT
Transformer 模型的核心是自注意力机制(self attention),其在序列长度上时间和存储的复杂度都在 O(N2)O(N2) 级别。随着大语言模型(LLMs)规模的不断扩大,为 LLM 配备更长的上下文背景,在工程实现上面临着非常大的挑战。 来自斯坦福大学计算机系与纽约州立大学布法罗分校的科研团队发表了一种新型的注意力算法,名叫 FlashAttention ,其不仅拥有比 PyT

幻方 AI 发布了其沉淀多年的深度学习套件 hfai ,吸引了众多同行研究员和开发者们咨询试用。整个套件的功能较多,而熟悉掌握了这套规则,是能够轻松地调用起平台的算力资源,从而高效完成训练任务的。 为此,我们专门创建了 “hfai 使用心法” 系列专辑,陆续为大家介绍 hfai 一些功能的设计思路和原理,帮助大家更好更快地习得心法,带着 hfai 这套“神功”游刃有余的应对深度学习作业的各项挑战,

幻方 AI 发布了其沉淀多年的深度学习套件 hfai ,吸引了众多同行研究员和开发者们咨询试用。整个套件的功能较多,而熟悉掌握了这套规则,是能够轻松地调用起平台的算力资源,从而高效完成训练任务的。为此,我们专门创建了 “hfai 使用心法” 系列专辑,陆续为大家介绍 hfai 一些功能的设计思路和原理,帮助大家更快上手 hfai,游刃有余的应对深度学习作业的各项挑战。 之前的文章为大家介绍了使用
幻方 AI 发布了其沉淀多年的深度学习套件 hfai,吸引了众多同行研究员和开发者们咨询试用。整个套件的功能较多,而熟悉掌握了这套规则,是能够轻松地调用起平台的算力资源,从而高效完成训练任务的。为此,我们专门创建了“hfai 使用心法”系列专辑,陆续为大家介绍 hfai 一些功能的设计思路和原理,帮助大家更快上手 hfai,游刃有余得应对深度学习作业的各项挑战。 本终章为大家连贯的演示 hfai

YOLO 系列模型在整个深度学习目标检测领域有举足轻重的地位,近些年模型性不断发展,工程落地中的应用也十分广泛。 最近来自美国的 Ultralytics 公司发布了第五代 YOLO 模型: YOLOv5。相比上代模型,YOLOv5 以更轻量的参数,更极致的推理速度,一经发布受到了学术界和工业界相关人士的广泛关注。 幻方 AI 最近在萤火集群上对该项工作进行了体验和优化。YOLOv5 没有相应的论文
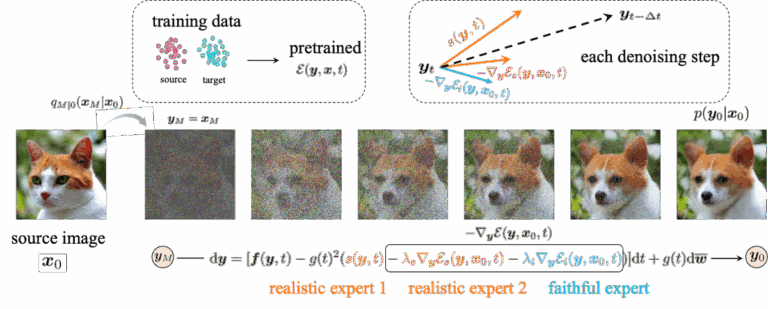
扩散模型作为一种新的深度生成模型,在图像生成领域取得了 SOTA 的效果,并且逐渐在诸多应用领域展现出强大的性能,如视频生成、分子图建模等。 最近来自人民大学李崇轩课题组的研究者们提出了一种基于能量函数的扩散模型生成指导方法 EGSDE。该方法旨在通过预定义的能量函数对预训练好的扩散模型进行指导,从而实现可控生成。现有指导生成方法如 classifier-guidance 等可以理解为 EGSDE
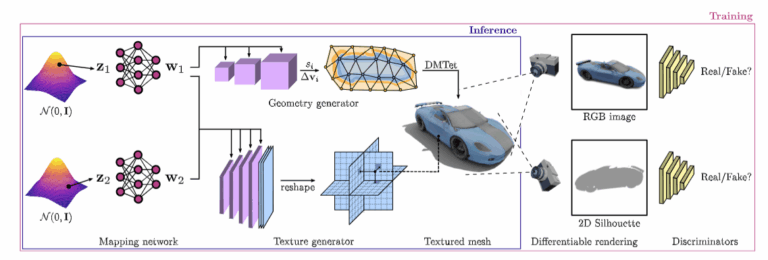
随着多个行业朝着大规模的 3D 虚拟世界发展,能够生成大量的、高质量的、多样的 3D 内容的工具是非常被需要的。英伟达的最新工作 GET3D 希望训练更好的 3D 生成模型,来生成下游任务可以直接使用的、保真纹理和复杂几何细节的 3D 模型。 幻方 AI 最近对这项工作进行了整理和优化,在幻方萤火二号上复现了实验。通过幻方自研的 3FS、hfreduce、算子,对模型训练进行提速,从单机多卡的训练
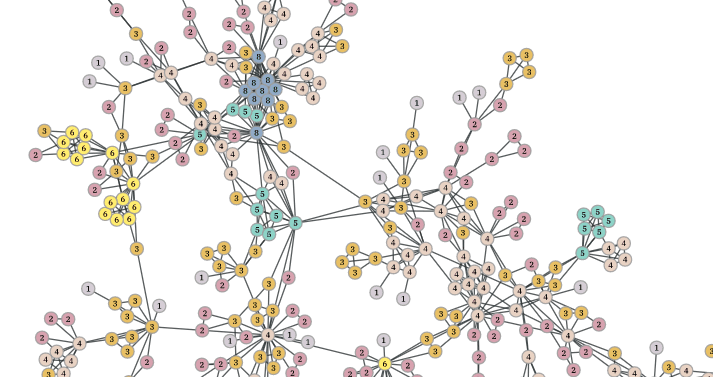
图(Graph)数据在现实世界中非常常见,例如社交网络、交通网络、物理系统等等,近几年图神经网络的发展将图数据的分析与深度神经网络结合,在越来越多的领域发挥出重要的作用,例如电商推荐、生物化学结构分析、反恐反诈风险控制等等。数据规模也呈现越来越大之势,动辄上千万节点规模的图,让很多图神经网络的训练需要探寻并行计算的方式以加速。 然而,图数据与视觉、自然语言等领域的数据不同,没有划分好的训练样本,很
haiscale (Highflyer AI Scale) 是一个轻量级的高性能并行训练工具库,其整合了幻方 AI 多年的并行训练研发优化经验,能够帮助 PyTorch 用户更加高效、便捷地在大规模集群上训练模型。 haiscale 中包含了以下几种工具: haiscale.ddp: 分布式数据并行工具,以幻方 AI 自研的 hfreduce 通信为后端,相比于 NCCL 能够获得更好的多卡拓展性
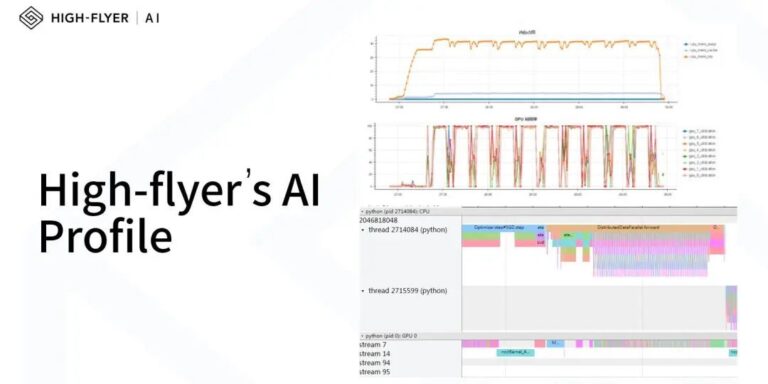
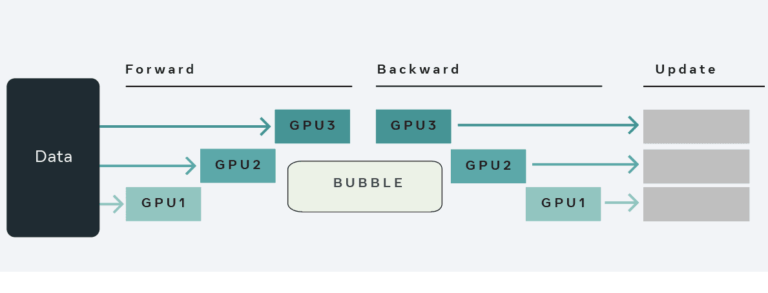
全世界都在给 GPT 的训练和推理算账,以至于微软会迫不及待地分享“每美元的推理能获得 2 倍的性能”的喜讯,其传递的信号或许是:一丁点的算力浪费,都在这场 AI 竞争里是致命的。 而越往后发展,模型训练效率的高低,越发成为科研人员不容忽视的难点。无论从加快训练测试更多参数,还是从节省研发成本的角度来说,低效的任务训练已经变得不可容忍。摆在眼前的,对于科研用户来说,一套趁手易用的模型性能分析工具,

“切勿错过AI的决定性时刻”这句 NVIDIA GTC 的广告语自周三起,一时间传遍全网。依照惯例,大会由熟悉的面孔黄仁勋围绕AI、芯片等科技,发布了一系列前沿技术产品。 今年幻方 AI 再度受邀,在 NVIDIA GTC 2023 大会中进行了一次技术主题分享。 自 2019 年起,我们为了满足自己科研作业的大规模算力需求,逐步构建了幻方萤火深度学习智算平台,其包括存储网络相关基础设施、分时调度