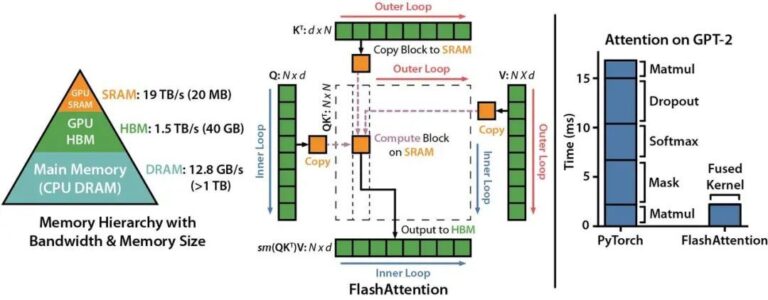
FlashAttention:具有 IO 感知,快速且内存高效的新型注意力算法
Transformer 模型的核心是自注意力机制(self attention),其在序列长度上时间和存储的复杂度都在 O(N2)O(N2) 级别。随着大语言模型(LLMs)规模的不断扩大,为 LLM 配备更长的上下文背景,在工程实现上面临着非常大的挑战。 来自斯坦福大学计算机系与纽约州立大学布法罗分校的科研团队发表了一种新型的注意力算法,名叫 FlashAttention ,其不仅拥有比 PyT
Transformer 模型的核心是自注意力机制(self attention),其在序列长度上时间和存储的复杂度都在 O(N2)O(N2) 级别。随着大语言模型(LLMs)规模的不断扩大,为 LLM 配备更长的上下文背景,在工程实现上面临着非常大的挑战。 来自斯坦福大学计算机系与纽约州立大学布法罗分校的科研团队发表了一种新型的注意力算法,名叫 FlashAttention ,其不仅拥有比 PyT
Transformer 模型的核心是自注意力机制(self attention),其在序列长度上时间和存储的复杂度都在 O(N2)O(N2) 级别。随着大语言模型(LLMs)规模的不断扩大,为 LLM 配备更长的上下文背景,在工程实现上面临着非常大的挑战。 来自斯坦福大学计算机系与纽约州立大学布法罗分校的科研团队发表了一种新型的注意力算法,名叫 FlashAttention ,其不仅拥有比 PyT
2018年,将近3亿参数的Bert模型横空出世,将NLP领域推向了新的高度。近年来人工智能领域的发展愈来愈趋向于对大模型的研究,各大AI巨头都纷纷发布了其拥有数千亿参数的大模型,诞生出了很多新的AI应用场景。另一方面,多种因素继续推动大模型的长足发展:1) 社会正经历着深度的数字化转型,大量的数据逐渐融合,催生出许多人工智能的应用场景和需求;2) 硬件技术不断进步:英伟达 A100 GPU,Go
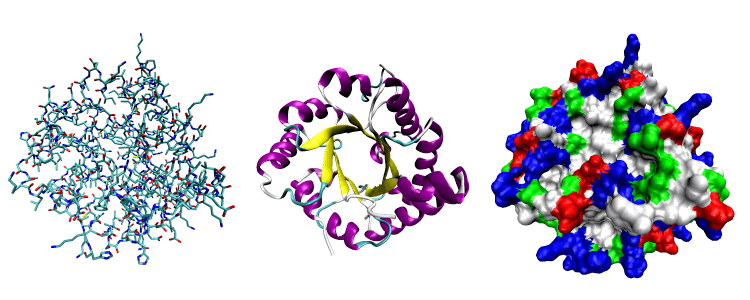
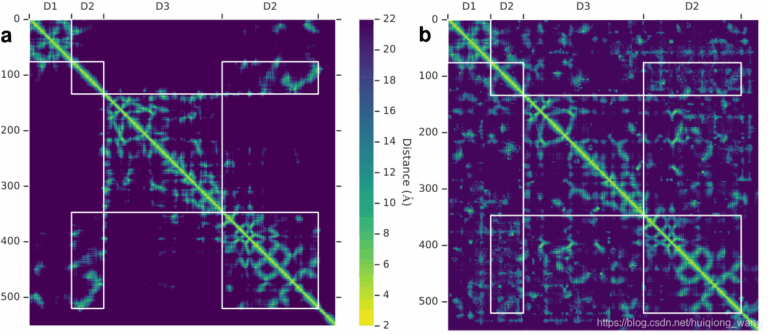
若说2021年人工智能学术界最令人振奋的成果,那么Alphafold可谓当之无愧。Alphafold2在CASP14 蛋白质预测挑战上取得了远远超出同类模型的准确率,并首次将蛋白质结构预测的精度提高到了原子级别——已经接近了实验测量的水准。 幻方AI团队在Alphafold2推出不久就在萤火二号平台成功将Alphafold2训练运行了起来,详情如我们上一期文章《萤火跑模型 | Alphafold
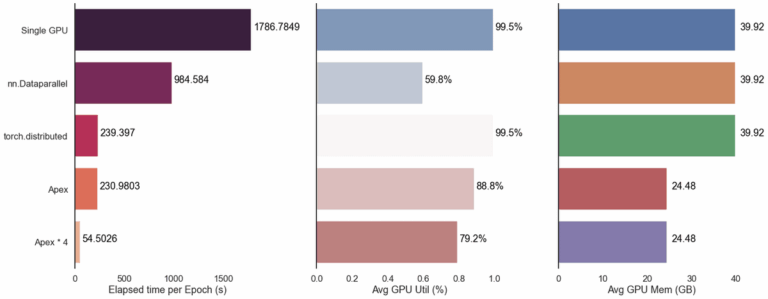
上一期文章讲到,幻方AI通过优化数据处理,采用特征预处理和特征裁切两种方式提高了Alphafold整体的训练性能。众所周知,幻方AI有很多并行训练加速神器,比如hfreduce,3FS,hfai.nn算子库等,它们是否能对Alphafold整体的训练进一步加速呢?本期文章将就这些问题进行试验。 hfreduce 之前的文章《幻方力量 | 模型并行训练工具:hfreduce》提到过,由于幻方AI架构
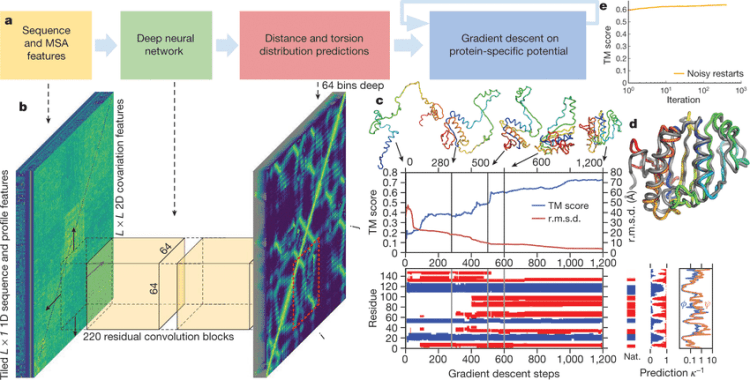
前两期文章展示了幻方AI对Alphafold的优化,采用特征预处理和特征裁切两种方式提高了Alphafold数据处理性能,通过并行训练加速神器进一步提高模型的训练速度,将Alphafold深度融合进幻方AI的集群特点中,发挥最大的计算效能。 那么从整体上看,在幻方萤火二号上训练Alphafold还有哪些需要我们注意的,以及未来同类型深度学习模型该如何优化?就这些话题,本期文章将和大家聊聊幻方AI的

如文章《幻方力量 | 高速文件系列 3FS》中所介绍的,幻方AI设计了一套非常适合深度学习训练的样本读取文件系统,3FS,其采用 Direct IO 和 RDMA Read 的读取方式,让模型训练在样本读取部分只用极小的 CPU 和内存开销,就可以获得超高的读取带宽,从而无需再训练过程中等待加载数据,更充分地利用起 GPU 的计算性能。 我们知道,文件系统一般分为客户端与服务端。在 3FS 文件系
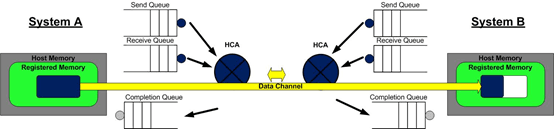
如文章《幻方力量 | 高速文件系列 3FS》中所介绍的,幻方AI设计了一套非常适合深度学习训练的样本读取文件系统,3FS,其采用 Direct IO 和 RDMA Read 的读取方式,让模型训练在样本读取部分只用极小的CPU和内存开销,就可以获得超高的读取带宽,从而无需再训练过程中等待加载数据,更充分地利用GPU的计算性能。 我们知道,文件系统一般分为客户端与服务端。在3FS文件系统中,客户端部
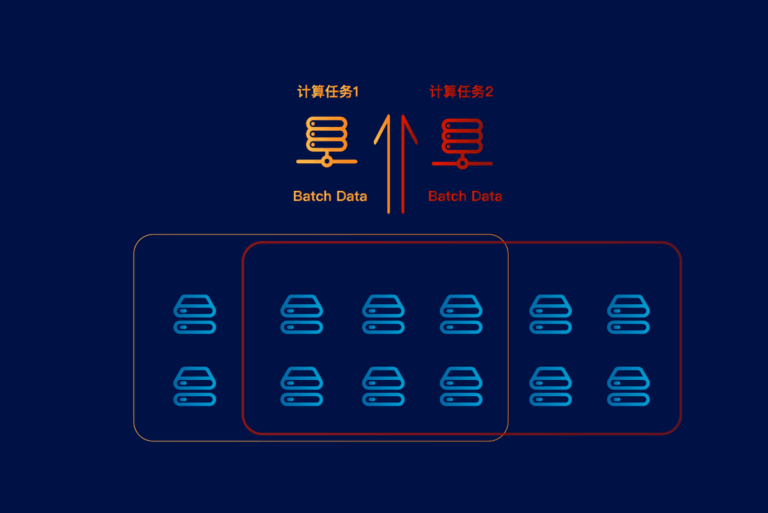
如文章《幻方力量 | 高速文件系列 3FS》中所介绍的,幻方AI设计了一套非常适合深度学习训练的样本读取文件系统,3FS,其采用Direct IO和RDMA Read的读取方式,让模型训练在样本读取部分只用极小的CPU和内存开销,就可以获得超高的读取带宽,从而无需再训练过程中等待加载数据,更充分地利用起GPU的计算性能。 然而,实际应用中会有很多我们之前没有预料到的问题,比如任务间互相影响的问题,
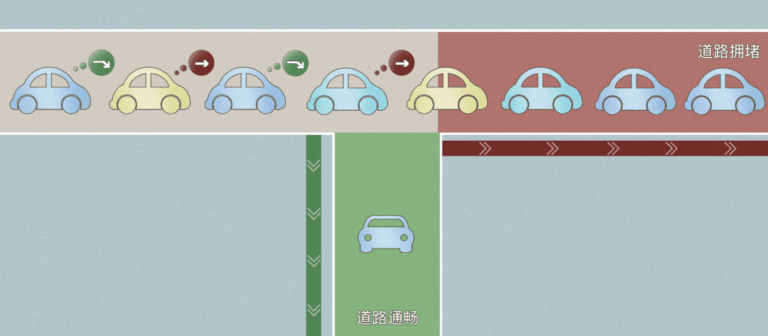
对于深度学习开发者和研究者们来说,高性能的算力是助力其研究成功的重要武器。对于影响深度学习训练快慢的因素,人们常常容易忽略网络传输在训练提速中的重要作用。特别是在大规模集群,分布式训练的场景中,网络的拥塞可能直接导致GPU算力的失效,就像空有一段段双向8车道的快速路,但如果道路规划凌乱,高速路也只能沦为大型停车场。 本期文章针对网络这个话题,分享一点幻方 AI 就这个方向上的思考和优化。 先聊聊网

幻方 AI 发布了其沉淀多年的深度学习套件 hfai ,吸引了众多同行研究员和开发者们咨询试用。整个套件的功能较多,而熟悉掌握了这套规则,是能够轻松地调用起平台的算力资源,从而高效完成训练任务的。 为此,我们专门创建了 “hfai 使用心法” 系列专辑,分集陆续为大家介绍 hfai 一些功能的设计思路和原理,帮助大家更好更快地习得心法,带着 hfai 这套“神功”游刃有余的应对深度学习作业的各项挑